
ليس من السهل اليوم اختيار نموذج ذكاء اصطناعي واحد يمكن وصفه بـ”الأفضل”. فالمستخدمون يميلون إلى النماذج التي تشبه أسلوب البشر، بينما يعتمد الباحثون والمطورون على نتائج الاختبارات العلمية، ويقيسون القدرة على التفكير، التحليل، البرمجة، ومعالجة السياق الطويل.
هذا التباين أنتج مشهدًا مثيرًا في 2025: نماذج تتصدر اختبارات الـ Benchmarks، لكن لا تتصدر قوائم الشعبية. ونماذج أخرى تحقق “حضورًا إنسانيًا” أكبر رغم محدودية قوتها التقنية.
وفي هذه المقالة، نجمع بين العالمين:
الاختبارات العلمية + تجارب المجتمع التقني + تفضيلات المستخدمين… لنصل إلى مقارنة واضحة وحيادية بين:
GPT-5.1-High – Gemini-3-Pro – Grok-4.1-Thinking – Claude-Sonnet-4.5.
المعيار الأول: اختبارات Benchmarks الرسمية (العنصر العلمي)
تعتمد الاختبارات الرسمية على قياس قدرات النماذج في مهام محدّدة مثل:
- MMLU (معرفة أكاديمية متعددة التخصصات)
- HumanEval (اختبار البرمجة)
- GPQA (أسئلة عالية الصعوبة)
- BIG-Bench
- Math Reasoning
- Codeforces
نتيجة هذه الاختبارات:
| الفئة | الأداء |
|---|---|
| GPT-5.1-High | الأعلى دقة في MMLU وGPQA، والأقوى في البرمجة HumanEval |
| Gemini-3-Pro | أداء ممتاز في المهام العامة والصور والفيديو |
| Grok-4.1-Thinking | جيد في المنطق لكنه أقل دقة من GPT وClaude |
| Claude-Sonnet-4.5 | أداء قوي جدًا في النصوص الطويلة والتحليل العميق |
الاستنتاج العلمي:
- GPT-5.1-High هو المتصدر في الاختبارات الأكاديمية والبرمجة والمنطق الخالص.
- Claude Sonnet قوي في التحليل العميق.
- Gemini يكتسب نقاطًا في الوسائط والسرعة.
- Grok أقل استقرارًا علميًا رغم تحسّن واضح.
المعيار الثاني: اختبارات المجتمع التقني (Developers & Researchers)
يعتمد المطوّرون في تقييمهم على مهام حقيقية:
- كتابة أكواد نظيفة
- إنتاج حلول كاملة
- تحليل البيانات
- كتابة مستندات تقنية
- حل مشكلات معقدة بخطوات واضحة
النتائج حسب آلاف التجارب:
GPT-5.1-High
- أقل معدل هلوسة
- أدق في البرمجة
- الأفضل في long context
- أفضل أداء في التحليل المالي والقانوني والعلمي
Claude-Sonnet-4.5
- الأفضل في الكتابة البحثية العميقة
- صياغة اللغة أكثر مرونة وجمالًا
- ممتاز في التعامل مع النصوص الطويلة جدًا
Gemini-3-Pro
- سريع جدًا
- قوي في الصور والفيديو
- أداء جيد في البرمجة لكنه ليس الأفضل
Grok-4.1-Thinking
- الأكثر شبهًا بالبشر في الحوار
- ممتاز في الأسلوب والنبرة
- أقل دقة في المهام التقنية
المعيار الثالث: تجربة المستخدم اليومي
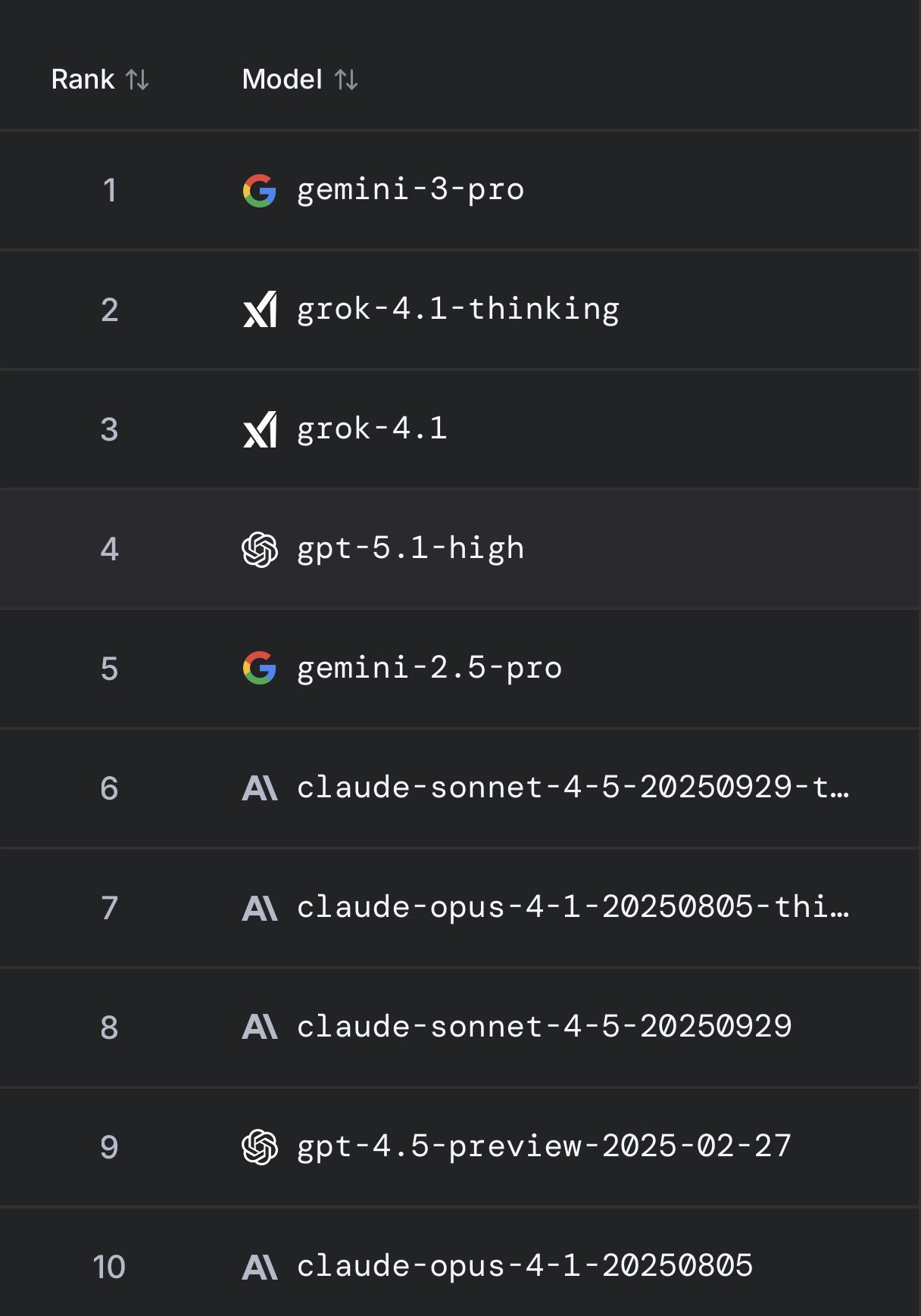
معيار يختلف تمامًا عن العلمي والتقني، ويعتمد على:
- سرعة الرد
- الأسلوب البشري
- المرونة في الحوار
- الطابع الشخصي
كيف يراها المستخدم العادي؟
- الأكثر شعبية: Grok-4.1-Thinking
- الأسرع: Gemini-3-Pro
- الأكثر دقة: GPT-5.1-High
- الأكثر شاعرية وإبداعًا: Claude-Sonnet-4.5
وهنا تظهر المفارقة:
قد لا يكون النموذج الأقوى هو الأكثر شعبية… وربما لهذا نجد Grok وGemini يتصدران قوائم الاستخدام رغم تفوق GPT في الدقة.
المقارنة النهائية من مجتمع ميتالسي
| الفئة | GPT-5.1-High | Gemini-3-Pro | Grok-4.1-Thinking | Claude-Sonnet-4.5 |
|---|---|---|---|---|
| الدقة | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| التحليل | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| البرمجة | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| الإبداع | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| السرعة | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| الكتابة الطويلة | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| الاستقرار (No Hallucination) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| المحادثة البشرية | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
الفارق بين العلم والشهرة
- يتقدّم GPT-5.1-High في كل ما يتعلق بالدقة والمنهجية.
- يتقدّم Gemini-3-Pro عندما يحتاج المستخدم لسرعة وفهم وسائط.
- يتصدّر Grok-4.1-Thinking في الأسلوب الإنساني والمرح.
- يتفوّق Claude-Sonnet-4.5 في النصوص العميقة والقصص والتحليل السردي.
لكن السوق ليس علمًا فقط… ولا تجربة مستخدم فقط.
ما نشهده اليوم هو انقسام واضح بين ما يفضله الناس وما تثبته الاختبارات.
الأسئلة الشائعة
ما هو أفضل نموذج ذكاء اصطناعي في 2025؟
أفضل نموذج يعتمد على الاستخدام: GPT-5.1-High للتحليل والبرمجة، Grok للمحادثة، Gemini للسرعة، Claude للكتابة الإبداعية.
هل نتائج Benchmarks تعكس الاستخدام الواقعي؟
تعكس جانبًا مهمًا، لكنها لا تقيس التجربة الشعورية للمستخدم، لذلك تختلف النتائج أحيانًا عن الواقع.
ما هو النموذج الأنسب للباحثين والطلاب؟
GPT-5.1-High يتفوّق في الدقة، والاستدلال، والكتابة البحثية المنهجية.
أي نموذج يقدم أفضل تجربة للمستخدم العادي؟
Grok-4.1-Thinking يُعد الأكثر سلاسة وقربًا من الأسلوب البشري.